无前端运营方案
前言
当一个业务在野蛮生长,从0-1的过程中,很多对应的运营工具会跟不上业务进步的步伐,可能前端/后端会没有资源去投入这样一个对于前期的ROI不高的地方去。但是,很多非频繁场景又需要这样一个平台去承接,譬如:
- 查看某用户的状态
- 查看某订单的状态
- 查看某产品当前的具体链路
- 当产生客诉问题时,快速定位客户问题,等等
上面的几个例子,都需要开发者通过人肉数据库的方式去查询,所以问题来了,能否用最少的资源,去快速搭建一个这样的平台呢?因为笔者是后端开发,所以希望有一个不需要关心前端页面,只开发后端代码即可——这就是无前端运营方案诞生的目的。
原理
为什么说是无前端运营平台呢?因为真的不需要前端的代码进行操作。
根据我对大部分运营平台的抽象,大部分运维平台都是一次性的操作,即用户不像业务系统一样,需要操作很多流程,而运营平台的用户大多数只会操作一次(如查询某个客户的信息,订正某条数据.etc)。所以可以把一次运维的生命周期理解为一次操作,而一次操作,则包含了操作类型:操作入参:操作方法:操作出参,四种一一对应的逻辑。
所以我对运维平台进行了抽象,抽象出了四个操作:
- 获取操作类型
- 根据操作类型获取要输入的字段
- 执行操作
- 获取该操作对应的输出
这四个步骤一旦在前端固定下来,用户就只需要再后端定义这四种操作即可完成对应的运维逻辑。
问题和方案
前面说到,需要四个步骤可以完成运维逻辑,那么问题就变成,如何将用户的逻辑通过编程语言表现出来。对于上面四个步骤来说,都有着或大或小的挑战
1. 获取操作类型
关于操作类型的存储结构有两个方案:
- 将用户定义的操作类型放到List数组中
- 将用户定义的操作类型和对应操作Handler放到Map中 ✅
同时,对于操作类型的注册也有几个方案:
- 通过系统接口,使用户必须返回某一操作的操作类型
- 通过文件配置,使用户显示的写入操作类型
- 通过注解,使用户将操作类型配置在对应的操作Handler中 ✅
2. 获取操作要输入的字段
这里有一个问题,就是每种操作的入参都是不一样的,系统如何拿到不同操作的不同入参字段以及他们的属性呢?
- 定义接口,使用户必须返回入参的属性(如字段是否必传,对客展示信息),然后系统初始化解析并在执行时返回给前端
- 使用文件配置,将操作对应的输入字段的属性配置在文件中
- 定义注解,使用户在字段类型的注解完成对子段属性的配置 ✅
3. 执行操作
在执行操作的过程中,有几个问题,
第一是如何将前端的无类型结构转换为Java的强类型?
- 前端传入map即可
- 后端因为可以通过接口或者范型拿到入参的class信息,直接反射new,然后赋值填充
第二是如何将用户的自定义出参转化为系统可以识别的出参?
- 通过反射拿到系统对应字段的已有值
- 然后结合用户配置的注解和已有的系统出参结构进行填充
4. 如何规范用户的自定义处理器
- 通过接口进行限制 ✅
- 通过方法级注解标明处理方法
流程实现
1. 系统初始工作
解析
在每个配置bean初始化后,都会去解析这个bean的入参和出参配置
- 通过范型获取入参和出参的真实类型
- 将用户通过注解配置的出/入参解析为系统内部定义的出入参数据结构
- 获取每个配置类通过注解配置的对应
OperationType - 对出入参的注解进行校验,约束用户行为
注册
采用策略模式,利用Spring的能力,将Bean在Spring初始化的后置就注册在系统的map中
- 如果bean的类型为
OperationConfig,系统则会去查找该类的OperationType, - 将ope作为key,config作为value,注册到map中
2. 系统执行流程
获取操作类型
- 通过之前注册的
OperationType,直接获取
获取请求参数
- 通过之前解析的入参数据结构直接获取
执行操作
- 将前端传来的参数转为用户自定义的入参实例**「重点」**
- 通过接口调用用户自己的业务处理操作
- 将用户的自定义出参转为系统内部的出参结构**「重点」**
- 将填充完成的系统内部出参结构封装诚响应传到前端
- 前端对对应的格式化响应进行渲染
3. 系统流程图
系统从编译期到运行期完成了数据结构的加载,解析和渲染。
这里多插一句,诸如Spring或者Mybatis这些中间件它们的普遍流程,都有以下几步:
- 先规范用户自定义的数据结构(如Spring和Mybatis都需要用户定义xml或者注解)
- 程序启动时加载并识别用户的数据结构,同时转为中间件自己的数据结构(如Spring的BeanDefinition)
- 程序启动后运行时,结合用户的不同请求和自己已有的数据结构,进行计算(该计算即是完成了中间件的主要功能)
从用户自定义数据结构,到系统将用户的自定义数据结构渲染为前端的页面,大概经过如下几个步骤:
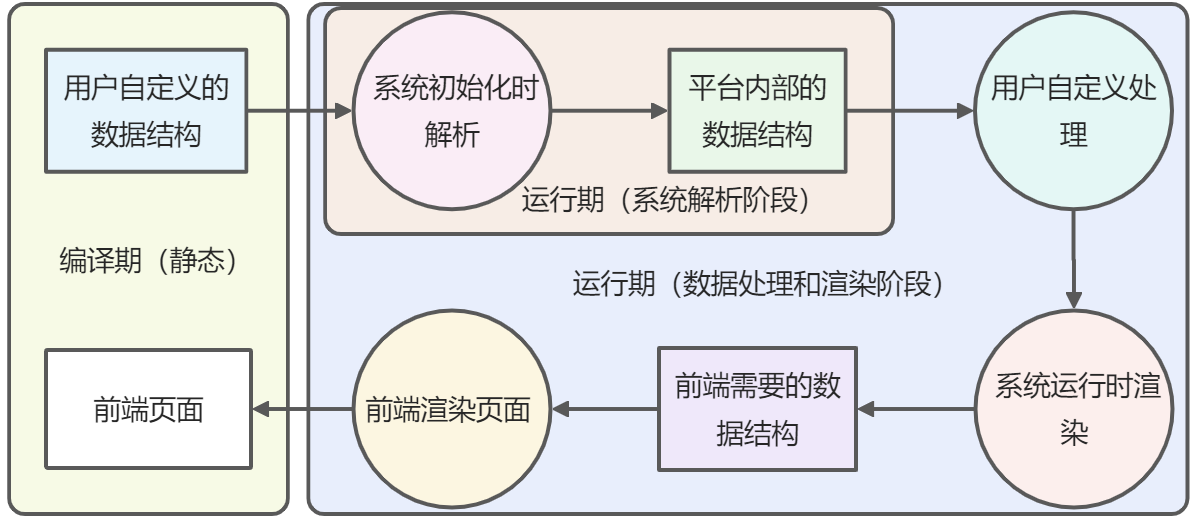
其他操作
1. 缓存
由于反射比较浪费性能,所以就多定义了几个字段去存储反射的元信息。【空间换时间】
2. 组合优于继承
通过组合的形式,来限制用户的操作空间,增强系统的健壮性。
3. 强类型和弱类型的转换
弱类型到强类型:
- map->反射
- json-反序列化
强类型到弱类型:(无)