00. 问题背景
先看下下面的代码是否有问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public static JSONObject parseConfig(String configStr) {
JSONObject config = new JSONObject();
if (!StringUtils.isEmpty(configStr)) {
JSONObject rawConfig = JSONObject.parseObject(configStr);
rawConfig.keySet().parallelStream().forEach(key -> {
Object obj = rawConfig.get(key);
if (JSONObject.class.equals(obj.getClass())) {
JSONObject path1Config = new JSONObject();
((JSONObject)obj).keySet().stream().forEach(path2Key -> {
JSONObject path2Config = ((JSONObject)obj).getJSONObject(path2Key);
Arrays.stream(path2Key.split(",")).forEach(keyDetail -> {
path1Config.put(keyDetail, path2Config);
});
});
config.put(key, path1Config);
} else {
config.put(key, obj);
}
});
}
return config;
}
|
眼尖的读者可能已经看到,这里使用了并行流,但是JSONObject底层是基于HashMap,是线程不安全的,所以就有可能存在隐患。
所以,就有可能存在一种现象,从配置文件中读取配置项的时候,为了图快,使用了Stream#parallelStream方法并发的put HashMap,然后在多线程的环境下,就会导致老线程put的值丢失的问题
01. 问题复现
下面,用一串简单的代码来复现下上述问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| public class MapTest {
public static void main(String[] args) {
List<Key> list = ImmutableList.of(Key.of(1), Key.of(2), Key.of(3),
Key.of(4), Key.of(9),Key.of(10));
AtomicInteger index = new AtomicInteger(0);
for (int i = 0; i < 100; i++) {
CountDownLatch tag = new CountDownLatch(6);
Map<Key, Integer> map = new HashMap<>(4);
for (int j = 0; j < 6; j++) {
new Thread(() -> {
synchronized (Object.class) {
if (list.size() <= index.get()) {
tag.countDown();
return;
}
}
map.put(list.get(index.getAndAdd(1)), 1);
tag.countDown();
}).start();
}
tag.await();
map.forEach((k,v) -> System.out.println(k));
}
}
private static class Key {
private int hash;
public static Key of(int hash) {
Key key = new Key();
key.hash = hash;
return key;
}
@Override
public boolean equals(Object o) {
return false;
}
@Override
public int hashCode() {
return hash;
}
@Override
public String toString() {
return "Key{" +
"hash=" + hash +
'}';
}
}
}
|
上面代码的逻辑很简单,用并行流put到HashMap中,如果处理完成后,将结果打印出来。上述逻辑循环100次,发现有一次的结果如下:
1
2
3
4
| Key{hash=1}
Key{hash=2}
Key{hash=3}
Key{hash=4}
|
发现竟然有一次循环中,多线程去put了6个值,但是HashMap中只有4个,这是为什么呢?
02. 问题原因
首先分析下每个Key的情况,根据HashMap的映射原理,再结合我们设置每个key的Hash值,我们可以发现,按照预期,在不扩容且CAP=4的情况下,正常的HashMap结构如下:
- Key1 -> Key9
- Key2 -> Key10
- Key3
- Key4
扩容的线程安全问题
当出现上面的异常情况的时候,我们可以判定,应该是在扩容情况下,老的值把新插入的值冲掉了,那么为什么会发生这种情况呢?我们先来看一下扩容的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| final Node<K,V>[] resize() {
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
else {
newTab[j] = loHead;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
|
从代码中我们可以看出来,当扩容的时候,新的空数组会直接复制给table,同时,老桶的值会直接赋值给新数组,这样在多线程下就会有问题,下面看一个例子:
线程1开始扩容,时间片用完,此时,其他线程抢占到时间片,把新的元素Key9和Key10放入了新的已经扩容的tab中。结构分别是:newTab[1]=Key9,newTab[2]=Key10
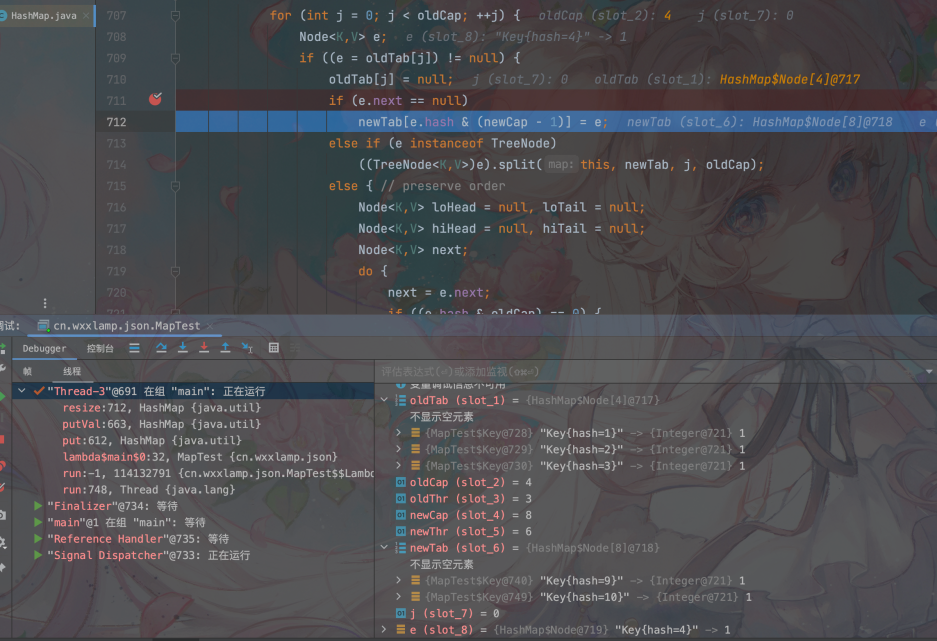
其他线程执行完毕,让出时间片,线程1继续执行扩容,当便利到oldTab[1]=Key1的时候,它会直接把newTab[1]=oldTab[1]=Key1,这里就可以看出,已经把newTab[1]=Key9给冲掉了
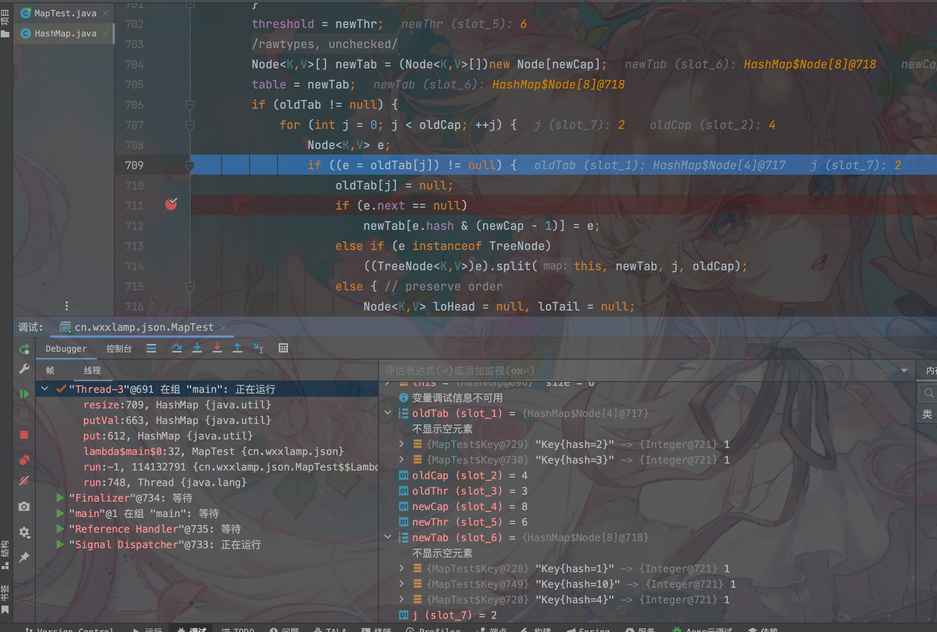
同理,newTab[2]=Key10也会被Key[2]冲掉
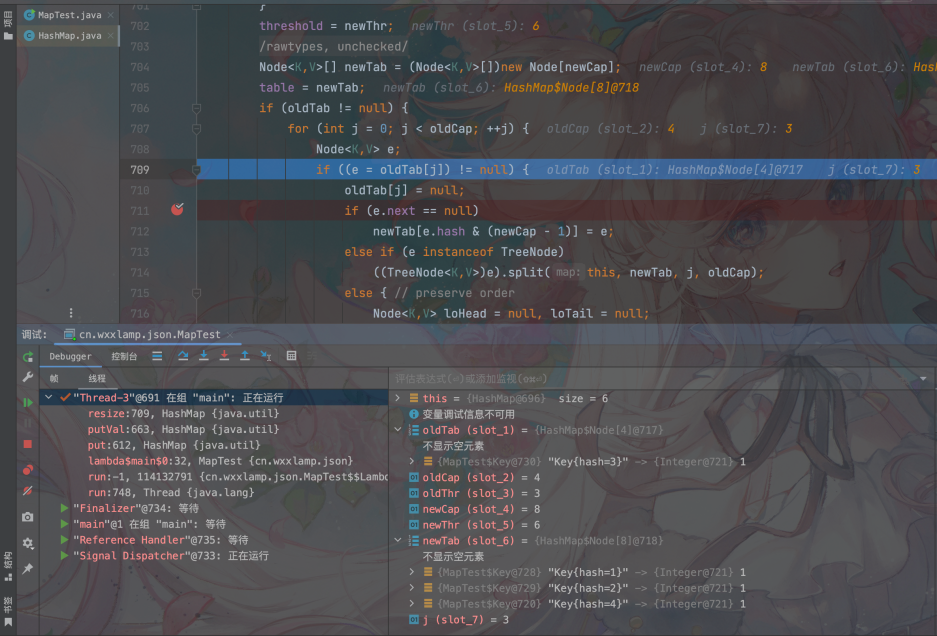
从最后的结果中我们可以看到,扩容过程中,其他线程插入的Key9和Key10两个值都被覆盖了。不过有一个点我们要注意,此时size仍然为6,但是Map中的元素却不是9对,这就是线程安全带来的问题
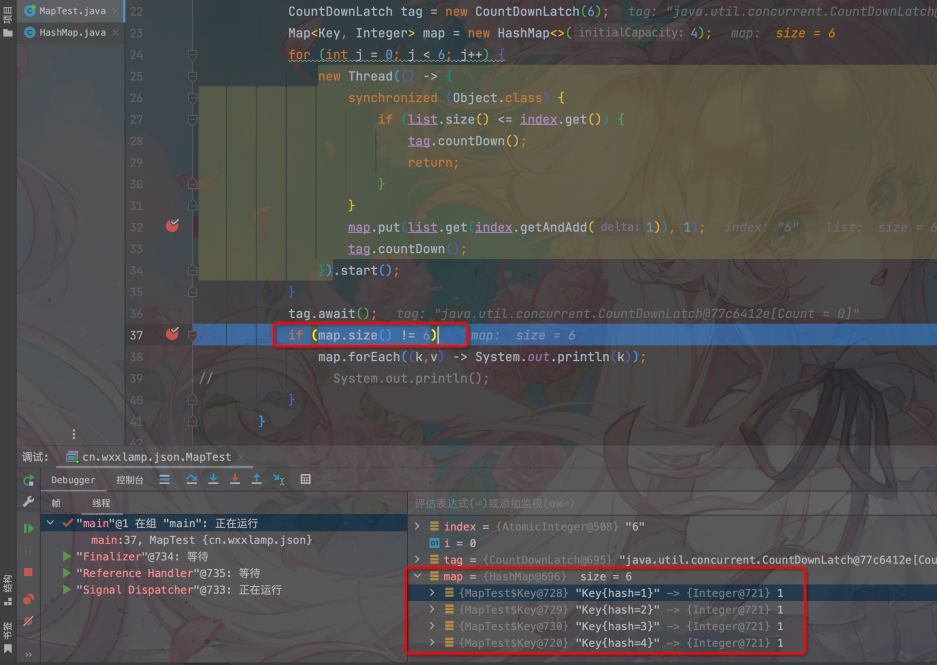
相同桶插入的线程安全问题
仍然是上面的例子,假如说Key1和Key9被两个线程同时插入,会触发什么问题呢?我重新跑了一下上面的例子,发下了会打印出如下代码:
1
2
3
4
5
| Key{hash=9}
Key{hash=10}
Key{hash=2}
Key{hash=3}
Key{hash=4}
|
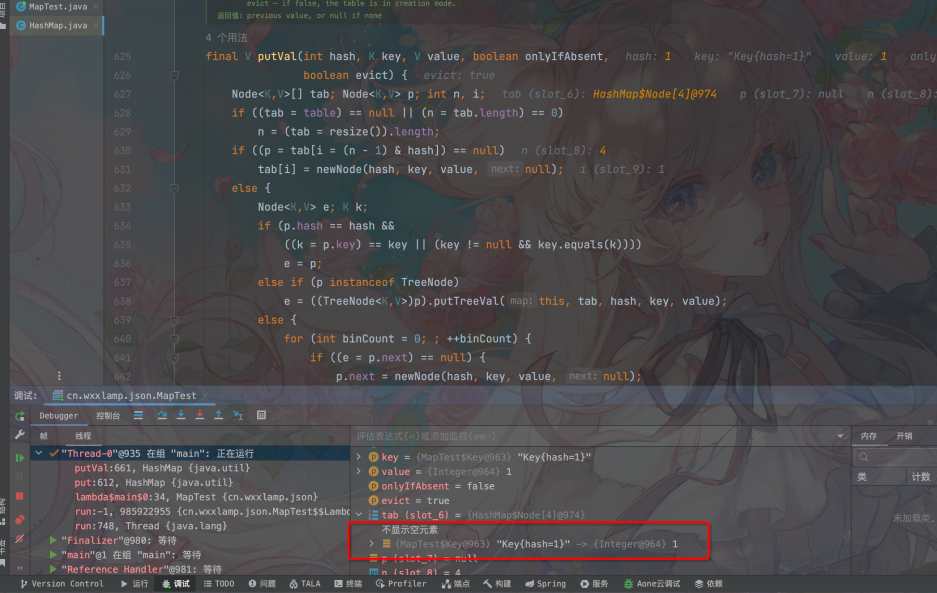
很显然Key1被Key9覆盖了,这个原因是什么呢?
这个和扩容是没有关系的,我们来看下put代码:
1
2
3
4
| if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
|
假如线程1刚执行完第三行,判断完成后,时间片用完,此时线程2进入执行,将tab[1]=Key9插入完成后结束,此时线程1恢复执行,那么线程1再执行tab[1]=Key1重新插入,就会覆盖掉线程2的值。看一下例子:
线程1执行tab[1]=Key1,此时时间片用完
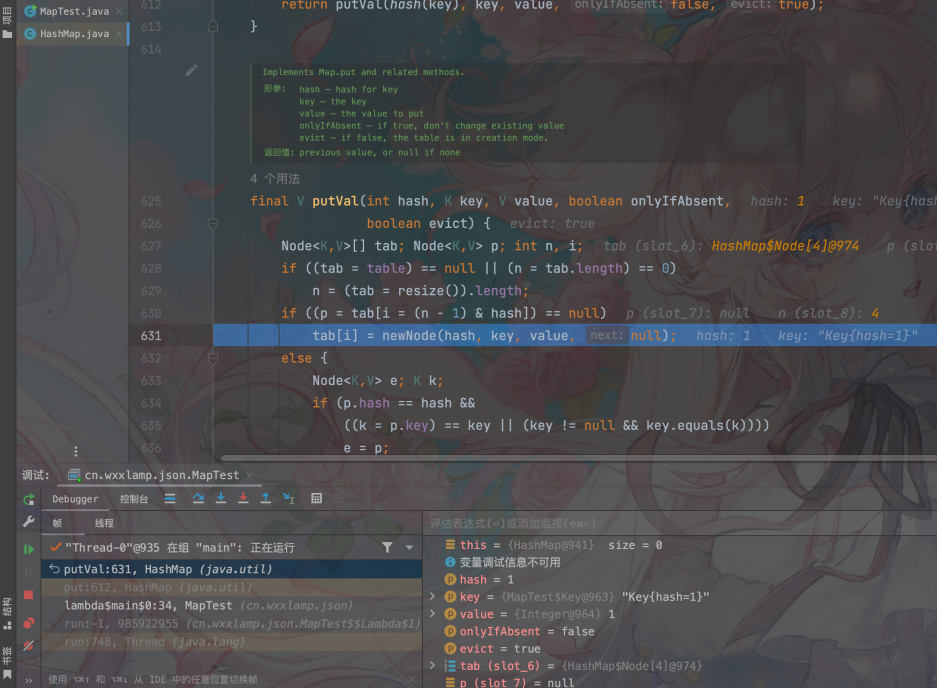
线程2执行tab[1]=Key9的插入,且执行完成:
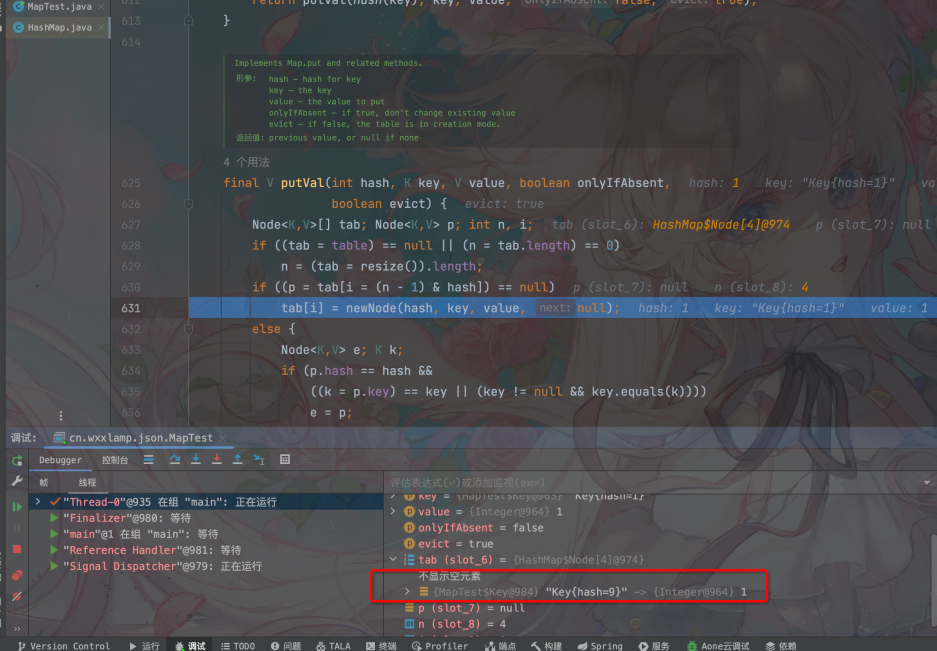
线程1恢复时间片,继续执行,原来的元素被覆盖掉
03. 解决方案
- 采用线程安全的Map,如ConcurrentHashMap
- 尽量不要使用parallelStream,因为它的行为是非常难以控制的 (《Effective Java》)
- 不要只使用流的foreach能力,要结合filter,collect等一起使用才会提高效率,如下:
1
2
| Map<Key, Integer> collect = list.parallelStream()
.collect(Collectors.toMap(e -> e, e -> 1));
|
04. 事后思考
很多人都知道,在并发情况下不能使用HashMap,而要使用ConcurrentHashMap,但是如果问为什么,可能刷过八股文的人会说,因为HashMap在并发情况扩容的情况下可能会出现死循环的问题。如果对HashMap不了解的人,可能会被这个回答所懵到,事实上,并发扩容所导致的死循环问题,只存在于1.7,而且在1.8的时候已经被修复了。那么,除了并发死循环,HashMap在并发调用下究竟会出现哪些线程安全问题呢?正像文中所说的
- 扩容导致的put失效问题,同时,元素的个数size和实际元素的个数不符合
- 如果线程1在在put元素之前时间片用完被切换,线程2刚好put了同一个桶中的元素,然后切换到线程1,那么此时线程1put的元素就会覆盖掉线程2刚才put的元素
除了这两种情况,一定还有其他情况,只不过笔者水平和时间有限,暂时就说这么多。
其实,再进一步,我们不妨思考一下,ConcurrentHashMap是如何解决上面的这些线程安全问题呢?