如何解决消息幂等问题
最近业务对接的时候,发现了一个问题:
消费上游某业务的的消息的时候,因为上游的特殊情况,导致在同一时间内会发出多条消息(状态变更消息,同一时间内状态变更多次),又因为消费的consumer没有做好幂等工作,就会导致消费消息的时候,会消费多次,体现在本问题的现象就是,落了两条数据
怎么解决呢?其实非常简单,核心的操作就是对冲突资源进行加锁。有如下几种方式
方案一:分布式锁
- 对当前的消费逻辑按照用户维度加分布式锁
- 如果当前已经消费过,则不再消费
- 如果没有消费过,则消费
伪代码如下:
1 | public void consume(Message msg) { |
方案二:数据库唯一索引
因为目前主流的web服务都是集群部署的,所以加锁必须要加分布式锁。但是对于数据库来说,虽然有分库分表,对于同一个分库分表键来讲,同一次消费的记录,一定会落到一个物理库的一张物理表上。
所以我们也可以借助单机数据的唯一索引,从数据库的角度加锁,如果数据库再插入数据库的时候,我们直接捕获Duplicate entry这样的异常即可。
方案三:特殊SQL语句
本质上也是依赖唯一索引的
insert ignore
insert ignore会忽略数据库中已经存在的数据(根据主键或者唯一索引判断),如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。
1 | insert ignore into sc (name,class,score) values ('张三','三年二班',90) |
执行上面的语句,会发现并没有报错,但是主键还是自动增长了。
replace into
replace into 首先尝试插入数据到表中。如果发现表中已经有此行数据(根据主键或者唯一索引判断),则先删除此行数据,然后插入新的数据,否则,直接插入新数据。
1 | replace into sc (name,class,score) values ('张三','三年二班',90); |
insert on duplicate key update
- 如果在insert into 语句末尾指定了on duplicate key update,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则在出现重复值的行执行UPDATE;如果不会导致重复的问题,则插入新行,跟普通的insert into一样。
- 如果有新记录被插入,则受影响行的值显示1;如果原有的记录被更新,则受影响行的值显示2;如果记录被更新前后值是一样的,则受影响行数的值显示0
1 | insert into sc (name,class,score) values ('张三','三年二班',90) on duplicate key update score=100; |
方案四:事务+排他锁
因为Innodb的读是通过MVCC实现的,所以正常的select语句是不会阻塞的,所以我们要借助数据库的事务能力,在查询的时候就会加锁,此时会导致其他查询被阻塞,然后如果没有查到就插入。SQL如下所示:
1 | select * from c where name = '张三' for update; |
其实方案四和方案一有点像,只不过方案一是在服务维度加锁,而本方案是用了数据库的锁。
下面针对于RR隔离级别举例:
索引和加锁的关系
主键索引
对有索引的where条件开启事务,如下:
1 | begin; |
此时加锁状态为:
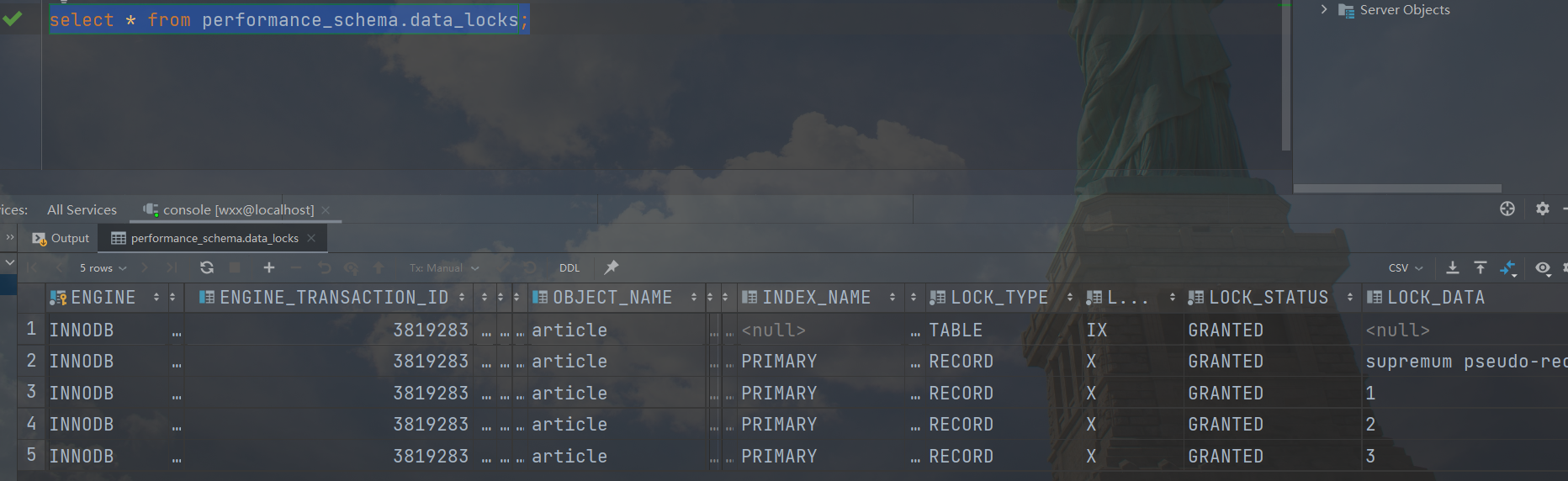
我们会发现,此时会为表和行均加锁,表是意向排他锁,行是标准排他锁(只锁记录,不锁间隙),此时毫无疑问,当在另一个事务执行加排他锁的Sql时,就会失败:
1 | select * from article where id = 3 for update ; |
PS,意向锁的作用:
如果没有「意向锁」,那么加「独占表锁」时,就需要遍历表里所有记录,查看是否有记录存在独占锁,这样效率会很慢。
那么有了「意向锁」,由于在对记录加独占锁前,先会加上表级别的意向独占锁,那么在加「独占表锁」时,直接查该表是否有意向独占锁,如果有就意味着表里已经有记录被加了独占锁,这样就不用去遍历表里的记录。
所以,意向锁的目的是为了快速判断表里是否有记录被加锁。
无索引
对有索引的where条件开启事务,如下:
1 | begin; |
此时加锁状态为: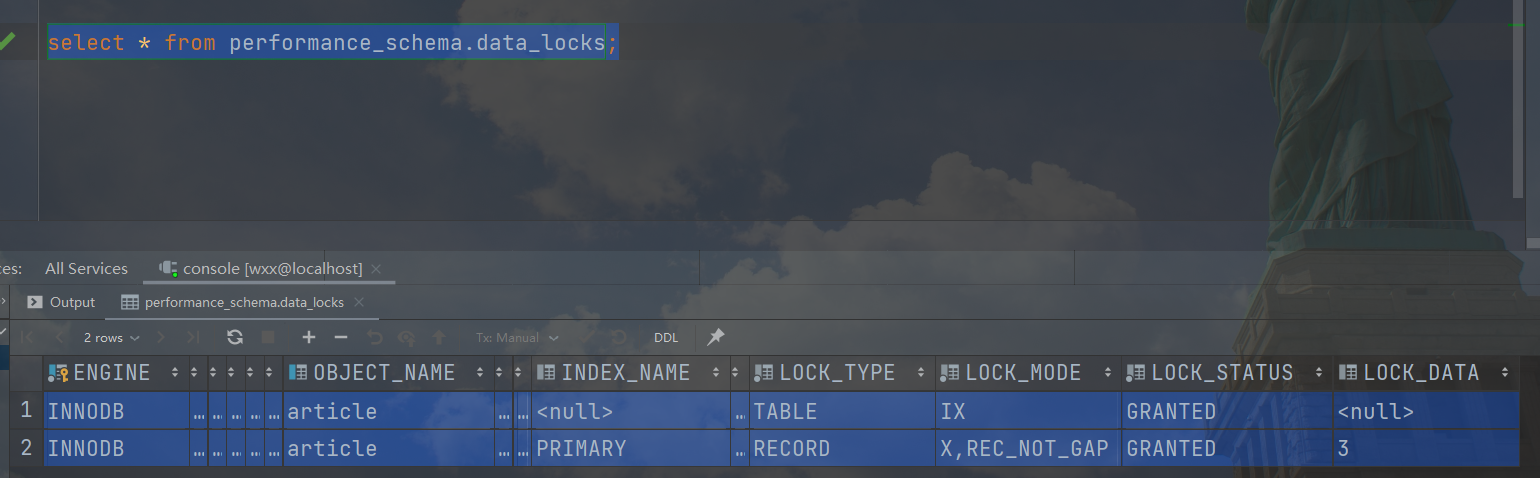
我们会发现,表也是加的意向排他锁。不过每条记录都会加一个完全排他锁(既锁行,也锁间隙),也就是会把全表都锁到。这个是非常危险的,意味着其他事务对该表的加锁操作都不能进行。
如果没有命中如何加锁
对于没有索引的case来说,加锁的逻辑和命中的是一样的,这里讲一下索引且没有命中,是如何加锁的。
SQL如下:
1 | begin; |
此时加锁的状态为: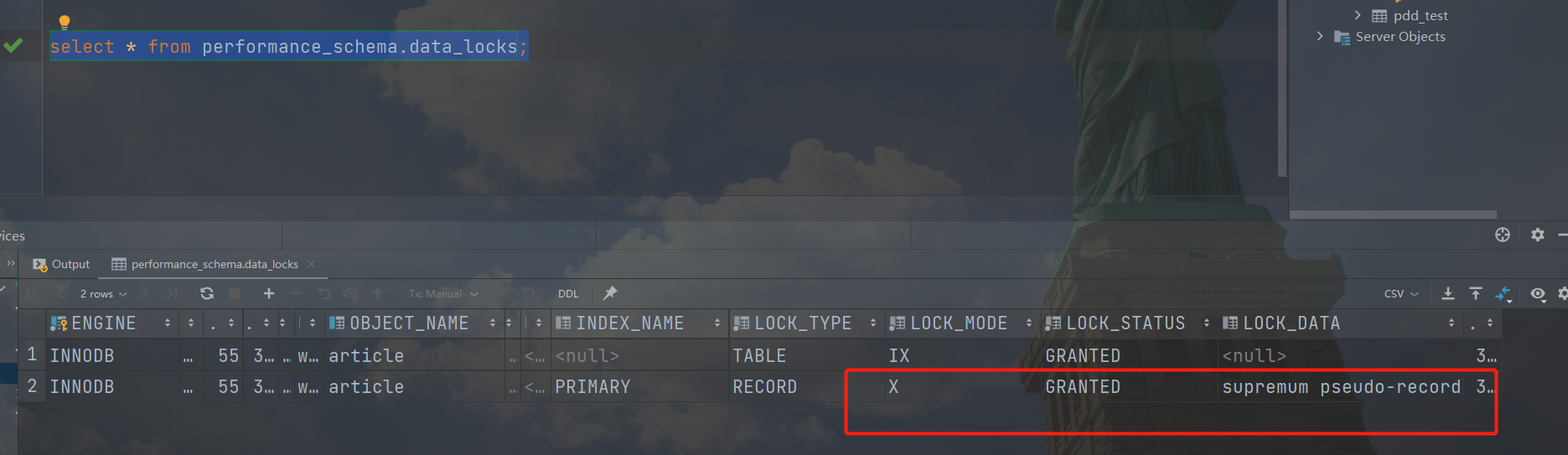
这时我们发现,它对行加了一个完全排他锁,排他锁的范围是3到正无穷区,这样说明在3到正无穷之间都是不能插入和更新的
primary key value(s) of the locked record if LOCK_TYPE=’RECORD’, otherwise NULL. This column contains the value(s) of the primary key column(s) in the locked row, formatted as a valid SQL string (ready to be copied to SQL commands). If there is no primary key then the InnoDB internal unique row ID number is used. If a gap lock is taken for key values or ranges above the largest value in the index, LOCK_DATA reports “supremum pseudo-record”. When the page containing the locked record is not in the buffer pool (in the case that it was paged out to disk while the lock was held), InnoDB does not fetch the page from disk, to avoid unnecessary disk operations. Instead, LOCK_DATA is set to NULL