大模型时代,7000字帮后端开发入门机器学习

前言
从2017年Transformer架构横空出世,再到2022年GPT的出现,人们愈发发现大模型的重要性,每一年仿佛都是LLM元年。在逐步步入AI时代的过程中,我感觉到十分的焦虑,担心被大模型替代,也感觉到兴奋,希望能通过LM做更多的事情。
但是我能够通过LLM做什么呢?我又需要了解什么呢?
在大模型时代以前,后端程序员一般需要掌握开发语言(Java、Go、Js等)、Mysql、Redis的架构知识就可以上手开发软件了。但是在AI时代,或者说是大模型时代,显然只掌握一般的开发语言已经不够看了。
LLM工程一句话说完就是使用各种PROMPT调用LLM,与此而来的有MCP、RAG等各种工程能力。如果想要快速的将LM能力嵌入到业务场景中,本质上和上古时期的CURD程序员一样,直接调用大模型厂商的开放接口即可。
但是只调用模型的API,如水中观月、镜里看花,始终是看不透本质和系统全貌的。私以为,对于后端程序员来说,要想融入AI时代,首先要做的不是调用LLM相关的API,而是要了解传统人工智能和机器学习相关的概念和原理,比如ML和DL到底是啥关系?CNN、RNN、Transformer这些架构是怎么演化的?。如果不了解这些基本的知识,就如同开发时代不了解操作系统、计算机网络一样——可以完成基本的编程,但是无法更进一步地窥到计算机世界的奇妙。
所以我花了一点时间,借助一些常见的问题,梳理了一下我对于人工智能和机器学习的理解。
你的AI我的AI好像不一样
这几年随着大模型的兴起,一切皆AI。狭义来说,AI就是人工智能,实现AI的核心人群被称为”算法工程师”(常常被称作调参侠)。大模型时代,很多人会直接用大模型代指AI,譬如罗永浩一贯的观点就是23年才迎来真正的AI时代。那么人工智能、机器学习、深度学习、大模型,它们之间的关系和区别在哪里呢?
根据李宏毅的理论,我们常认为人工智能(Artificial Intelligence, AI)是最终要达到的目标,而主要手段则是机器学习(Machine Learning, ML)。计算机视觉(Computer Vision, CV)、自然语言处理(Natural Language Processing, NLP)等则是一些具体的应用。
从一个外行的角度出发,ML是一个泛称,其核心逻辑是”通过数据训练模型,让计算机自主学习规律以完成特定任务”。在ML的技术分支中,深度学习(Deep Learning, DL)是当前最核心、最主流的方向。深度学习以”深度神经网络”为核心架构,拥有多层多个神经元进行学习,神经网络从基础到复杂,分为基本的前馈神经网络(Feedforward Neural Network, FNN)、处理序列数据的循环神经网络(Recurrent Neural Network, RNN)、处理空间数据的卷积神经网络(Convolutional Neural Network, CNN)等。Google提出的Transformer架构则重构了原来RNN和CNN序列式处理的原则,采用Self Attention机制,解决了序列依赖的问题,使得模型不仅可以感知token之间的关系,也具备并行训练的能力。
至于大模型(Large Models, LM),它的大不仅是指的训练模型的参数大,也是指的训练依赖的数据多。正是借助于Transformer的能力,才使得模型变”大”成为了可能。大模型最开始的一个分支是大语言模型(Large Language Models, LLM),起源于NLP领域,适用于文生文等各种NLP的传统任务。不过随着LM多模态的发展,目前LM也不仅局限于NLP领域,而是为了实现AI这个目标触及到了应用的各个方面。
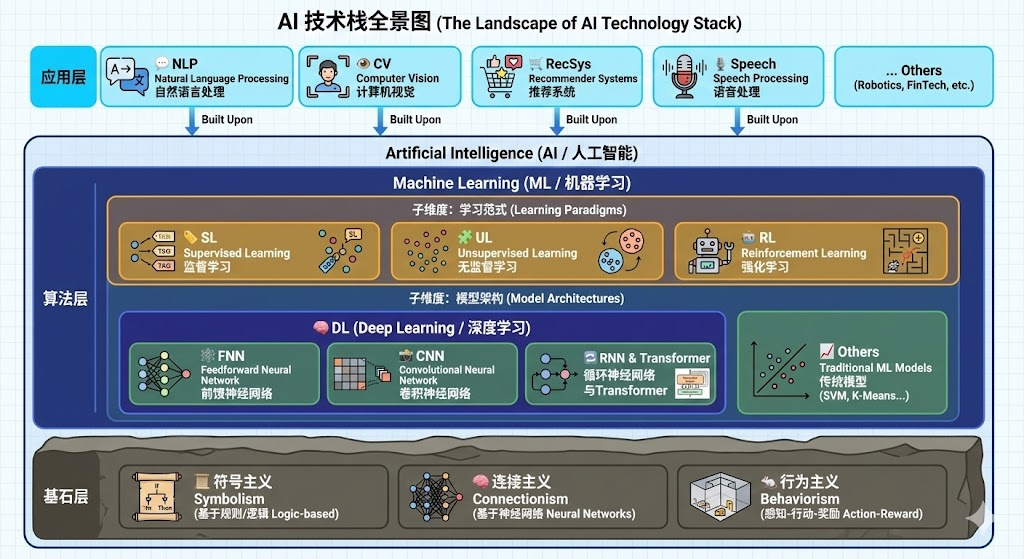
机器学习能干什么事
虽然从应用的领域来讲,基于ML的LLM具备文生文、文生图、图生文等能力。但是追其根本,所有的应用层任务都会回归到”回归(Regression)”和”分类(classification)”两种任务上来。
所谓回归,类似于y=kx+b,根据输入的不同,会输出不同的值。回归任务常用于预测(如天气预报、房价和股票走势等)。 而分类则是在回归的基础上,通过激活或者分类函数,将结果分成某几类(譬如正数和负数两类)。分类任务常用于打标签等。
我们常说的搜推广中的推荐,就属于分类任务。而众所周知,大模型虽然会根据预测的概率生成文字,但其本质是在词表中(譬如50000个单词)预测下一个词(Token),所以大模型属于分类任务。
模型到底是个什么东东
随着大模型的普及,几乎每个人都听说过”模型”两个字。那么模型究竟是什么。
从宏观上理解,模型是一个黑盒。通过为模型提供输入,模型内部通过计算后,最后输出得到最终的输出结果。
从huggingface的开源模型库中可以看到,模型长这样:
模型内部是一系列的参数(weight),模型思考的过程,本质上就是结合输入的token进行一系列的向量运算(主要是矩阵乘法)。在大模型时代,我们可以更加聚焦一点,认为模型内部就是由一堆神经元组成的神经网络。那么,神经元又是个什么东东?
神经元和神经网络
神经元
神经元简单理解就是一个计算单元。假定输入为x,神经元可以是wx+b。经过神经元计算的输出就可以是y。只不过x不是高中数学中学到的一个变量,而是和输入相关的n个变量组成的一个一维向量:
$ y = \sigma(w_1 x_1 + w_2 x_2 + b) $,即:
$ y = \sigma([w_1, w_2] \cdot \begin{bmatrix} x_1 \ x_2 \end{bmatrix} + b) $
在上面的表达式中,$ x_1 $和$ x_2 $是指输入的特征,譬如针对一个天气预报预测模型,$ x_1 $可能是湿度,$ x_2 $可能是温度。$ w_1 $和$ w_2 $指的是变量的权重,也是我们平常说的”参数”,所谓的训练,就是不断调整$ w $(和其他参数)的值,使得输出$ y $更贴近于真实值(loss更低)。$ b $指的是偏置(通俗一点说就是截距),可以对计算数据进行增加或者减少。括号外面的符号是sigma ($ \sigma $),它用来表示激活函数,常见的激活函数有 Sigmoid($ \sigma(x) \in (0,1) $)、ReLU($ relu(x) = max(0,x) $)等。激活函数用来控制输出,使得结果变得不再线性。
形象化的神经元如下所示:
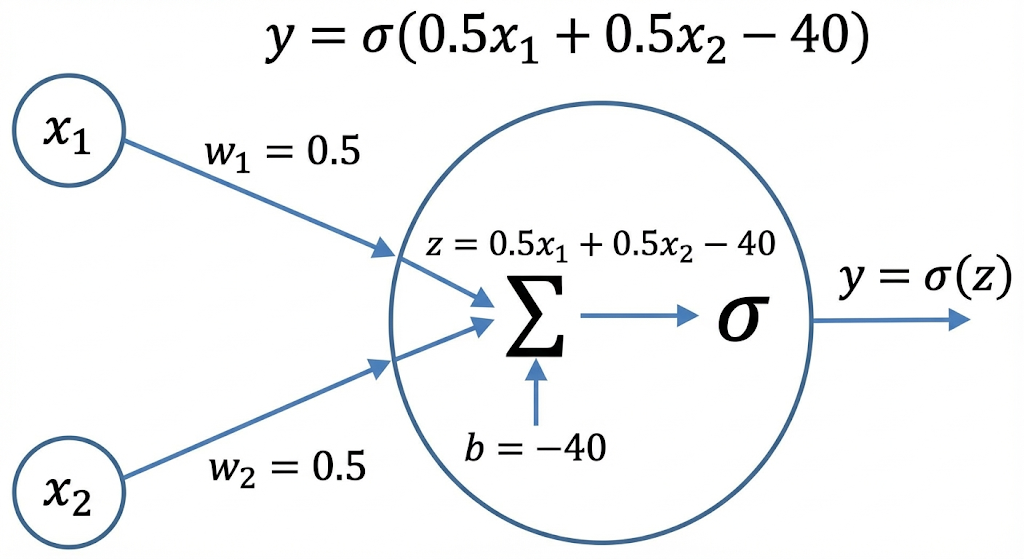
简单神经元使用python代码表达如下:
1 | import torch |
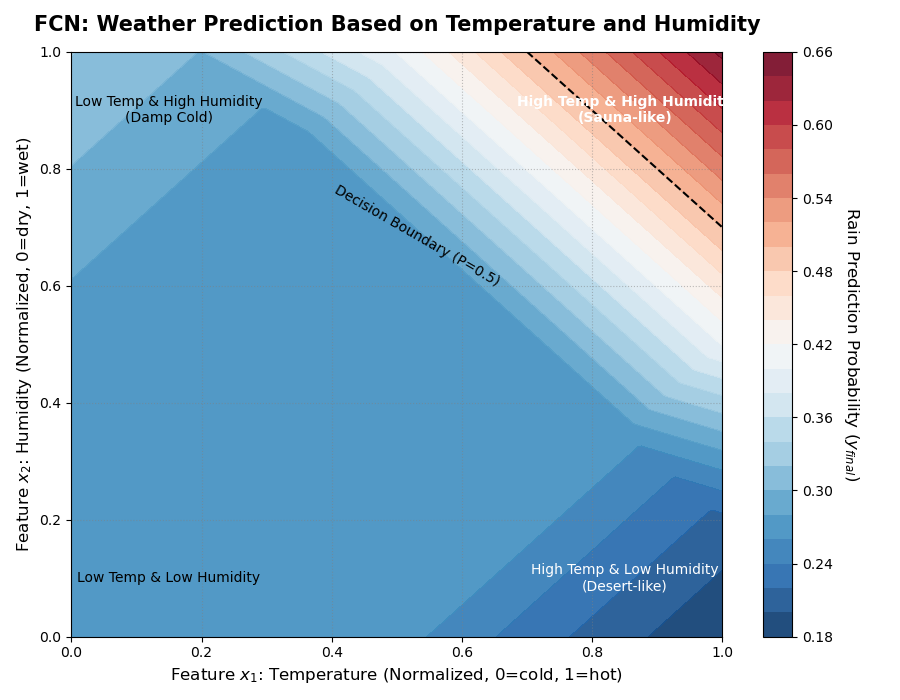
假设训练出来的参数为 $ w_1=0.5, w_2=0.5, b=-40 $,即:$ y = \sigma(0.5 x_1 + 0.5 x_2 - 40) $。我们会得到预测趋势如图所示:
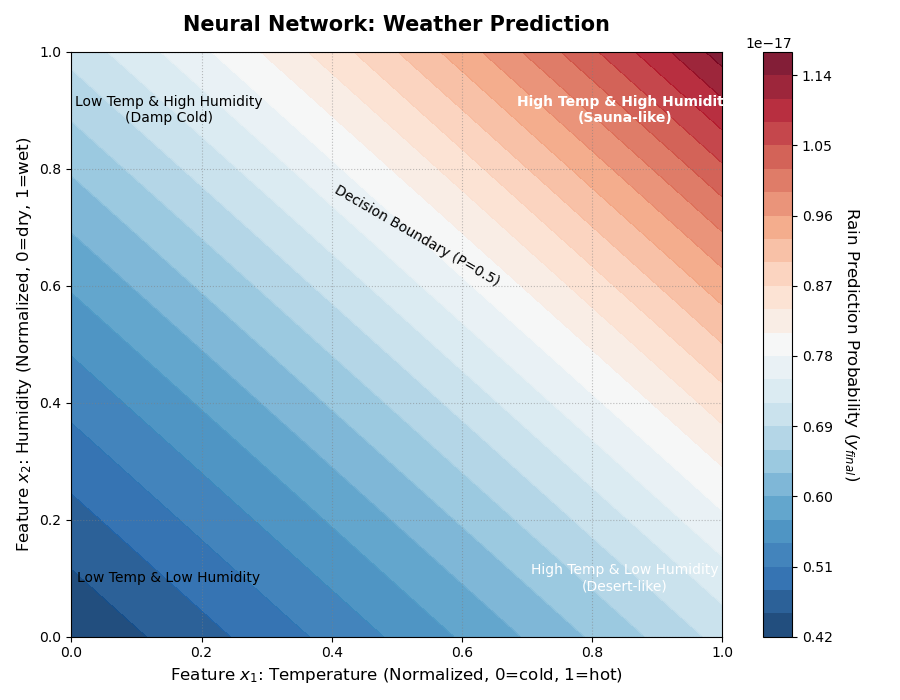
从上的图中,我们会得到结论:温度越高、湿度越大、越容易下雨。下面我们来分析:
- 情况 A (桑拿天): $ 0.9 \times 0.5 + 0.9 \times 0.5 = 0.9 $ (预测下雨,正确 ✅)
- 情况 B (沙漠): $ 0.9 \times 0.5 + 0.0 \times 0.5 = 0.45 $ (预测不下雨,正确 ✅)
- 情况 C (极端高温干燥): 假设温度超级高 $ x_1=2.0 $:
- $ 2.0 \times 0.5 + 0.0 \times 0.5 = 1.0 $ (预测下雨,错误 ❌)
我们发现,即使训练出来的w和b是最优的,得到的一定是一个线性的结果。但是,天气预报不是一件线性预测的事情。所以我们就需要尝试其他工具来解决问题。
全连接神经网络
可以发现,简单的神经元只能做线性回归。但是世界其实是很复杂的,所以我们就需要尝试将多个神经元链接在一起,执行更复杂的任务。
所以从天气预报的例子我们可以得知,天气预报不是一件线性预测的事情。预测天气的特征之间是有关系的,而我们无法通过单一的神经元获取到这些关系。从工程的角度来讲,遇事不决就加一个中间层。既然温度和湿度之间是有关系的,我们就把温度和湿度进行关联,形成多个中间特征,再由这些中间特征产生最后的结果。如下图表示:
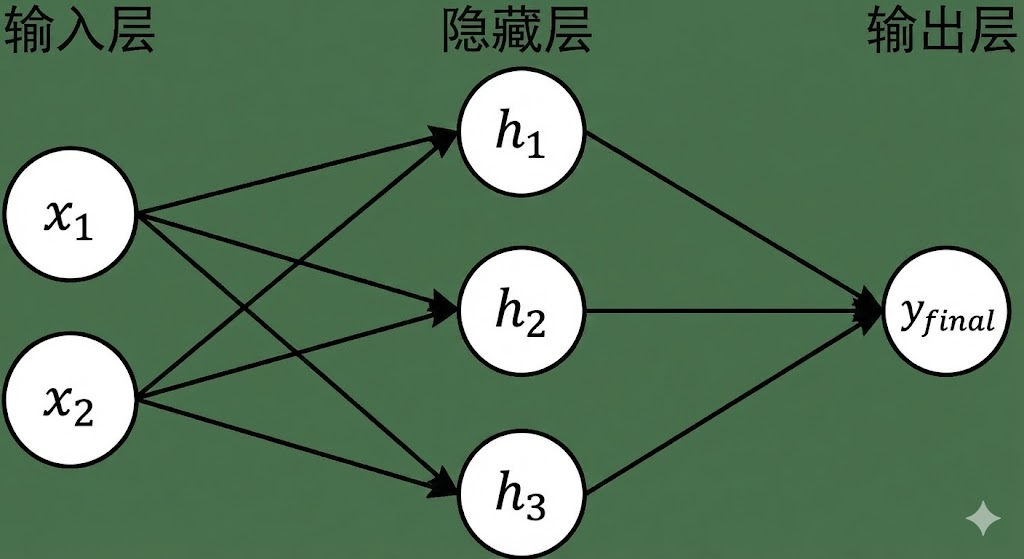
转换成简单的数学公式,如下:
$ h_1 = \sigma(w_{11} x_1 + w_{12} x_2 + b_1) \
h_2 = \sigma(w_{21} x_1 + w_{22} x_2 + b_2) \
h_3 = \sigma(w_{31} x_1 + w_{32} x_2 + b_3) \
y_{final} = \sigma(v_1 h_1 + v_{2} h_2 + v_3 h_3 + b_4)$
因为上面的公式可以尽可能的将$ x_1, x_2 $全部关联起来,所以我们把上面的网络称为全连接神经网络(Fully connected network),它是目前深度学习的基础。如果把上面的FCN带入到我们湿度和温度的例子中,我们令$ h_1 $负责桑拿天属性、$ h_2 $负责湿冷天属性、$ h_3 $负责干热天属性,假定训练结果如下:
$ h_1 = \sigma(x_1 + x_2 -1.2) \
h_2 = \sigma(-x_1 + x_2 -0.5) \
h_3 = \sigma(x_1 - x_2 - 1.0) \
y_{final} = \sigma(2 h_1 + 0.5 h_2 - h_3 -1)
$
我们可以得到如下的预测图:可以发现经过中间层之后,就不会再出现”高温干燥”也会下雨的情况了。
回到数学公式中来看,如果有多个特征、多层神经元,上面的表达未免太过复杂,所以借助矩阵相乘的空间变换特性(旋转、缩放、扭曲),我们可以把上述的中间隐藏层做如下转换:
$ h = \begin{bmatrix} h_1 \ h_2 \ h_3 \end{bmatrix} = \begin{bmatrix}
\sigma(w_{1,1}x_1 + w_{1,2}x_2 + b_1) \
\sigma(w_{2,1}x_1 + w_{2,2}x_2 + b_2) \
\sigma(w_{3,1}x_1 + w_{3,2}x_2 + b_3)
\end{bmatrix} = \sigma(\begin{bmatrix}
w_{1,1} & w_{1,2} \
w_{2,1} & w_{2,2} \
w_{3,1} & w_{3,2}
\end{bmatrix} \cdot \begin{bmatrix} x_1 \ x_2 \end{bmatrix} + \begin{bmatrix} b_1 \ b_2 \ b_3 \end{bmatrix}) = \sigma(Wx + b) $,
所以可以得到最终的输出为:
$ y_{final} = \sigma( \underbrace{\begin{bmatrix} v_1 & v_2 & v_3 \end{bmatrix}}{W_2} \cdot \underbrace{\begin{bmatrix} h_1 \ h_2 \ h_3 \end{bmatrix}}{h} + b_4 ) $ 。
但是,在用代码训练的时候,我们要尽可能的并行做训练,所以就有分批这个概念。即,我们不会每次只算一条特征,而是把特征打批,一次计算多个,公式如下:
$ \begin{bmatrix}
h_{1,1} & h_{1,2} & h_{1,3} \
h_{2,1} & h_{2,2} & h_{2,3} \
h_{3,1} & h_{3,2} & h_{3,3} \
h_{4,1} & h_{4,2} & h_{4,3} \
h_{5,1} & h_{5,2} & h_{5,3}
\end{bmatrix} = \begin{bmatrix}
x_{1,1} & x_{1,2} \
x_{2,1} & x_{2,2} \
x_{3,1} & x_{3,2} \
x_{4,1} & x_{4,2} \
x_{5,1} & x_{5,2}
\end{bmatrix}{\text{Data (5 days)}}
\cdot
\begin{bmatrix}
w{1,1} & w_{2,1} & w_{3,1} \
w_{1,2} & w_{2,2} & w_{3,2}
\end{bmatrix}{W^T}
+
\begin{bmatrix}
b_1 & b_2 & b_3
\end{bmatrix}{\text{Bias}} $,
即:
$ h_{\text{单层输出}} = xW^T + b $
用代码表达如下:
1 | class SimpleFCN(nn.Module): |
CNN和RNN
有了FCN之后,理论上我们可以通过大量的数据训练出任何我们想要得到的结果。但是因为FCN是全连接的,这里面主要会有三个缺点:
- 参数冗余与计算量大:默认所有的神经元与上一层所有神经元都有连接,这会导致参数量的急剧增加。特别是当输入数据的维度很高(如高分辨率图像)或网络层数加深时,容易引起参数爆炸,直接撑爆计算机的内存。
- 忽略局部特征:因为FCN每次计算必须感知所有输入,它没有”空间局部性“的概念。这意味着它无法像人眼一样,先关注局部的特征(如图像中的线条、纹理),再组合成整体,而是”囫囵吞枣”地处理所有信息。
- 没办法感知”顺序”:在FCN的逻辑里,所有的输入特征是平行的,没办法感知哪个”先来”,哪个”后到”。 譬如当我们把一个Sentence作为Input丢到FCN里,FCN无法有效捕捉到Token前后的时序依赖关系,难以理解上下文的语义。
CNN
CNN即卷积神经网络(Convolutional Neural Network),它的核心是有一个卷积层,这个卷积层不会像FCN一样每个神经元都连接所有的参数,而是”选择性”地连接。
假如说有一张33像素的图片,如果我们使用FCN来识别该图片,就只能把33的像素铺平成9个参数,然后让这个9个参数进行全连接的线性运算,单一神经元的数学表达如下:
$ \begin{bmatrix}
x_1 & x_2 & x_3 \
x_4 & x_5 & x_6 \
x_7 & x_8 & x_9
\end{bmatrix}
\xrightarrow{\text{Flatten}}
[x_1, x_2, x_3, x_4, x_5, x_6, x_7, x_8, x_9] $,
$ h = \sigma(w_{1} x_1 + w_{2} x_2 + … + w_n x_n + … + w_9 x_9 + b) \ $
因为铺平的原因,导致参数之间几乎丧失了位置和空间信息,所以用FCN不仅会导致参数爆炸,同时也会使得识别参数的精确度受到影响。
对于图片来说,要想保留位置信息,我们就不能把输入像素铺平,而是要考虑像素参数之间的关系,同时为了防止每次计算都计算所有像素点,我们需要设置一个窗口,每个神经元只计算窗口内的值,假定我们的窗口是2x2,那么可以用如下表示:
$ \text{Kernel} =
\begin{bmatrix}
w_{1,1} & w_{1,2} \
w_{2,1} & w_{2,2}
\end{bmatrix} $
这里的Kernel即为卷积核,此时神经元的表达如下:
$ h = \sigma(w_{1,1} x_1 + w_{1,2} x_2 + w_{2,1} x_4 + w_{2,2} x_5 + b) \ $
可以看到,对于卷积核的神经元来说,有两个特点,第一是不会识别所有的参数;第二是可以精确感知到位置相关的信息。
卷积核的核心就是关心局部的特征而不是所有的特征。我们可以把卷积核理解成一个局部特征,假如说$ K_h $拥有22的参数,他的作用是专门识别”竖线”。$ K_h $会上下左右平移遍历每一个22的像素点,找到可能是”竖线”的像素图块。
一张图片不止有一个特征,所以我们会有多个卷积核($ K_1,…, K_n $),每个卷积核分别代表不同的特征,譬如有些卷积核负责识别线条、有些负责识别颜色,等等。
一个简单的CNN代码如下所示:
1 | import torch |
RNN
FCN将用户输入的特征二次加工成通用特征、CNN进一步处理了部分特征关联的问题。但是FCN和CNN都没有解决不同时间特征关联的问题。请考虑下面一个场景:
在做机器翻译的时候,我们尝试将”Book a hotel” 和 “I like book” 翻译成中文
如果我们直接使用FCN训练上面的句子,那就需要把 “Book a hotel” 的每个token都作为参数进行训练,这固然是可行的,但是一旦翻译的句子变成了 “I like book”,原来训练的FCN模型就完全不可用(这是因为FCN的入参是固定的)。所以在输入变化的场景,只靠FCN是完全不行的。
既然整个句子训练不可行,所以我们就必须将句子拆分开成单词来训练,即模型的输入不能像FCN一样全部输入,而是滚动的输入。但是因为 “book” 在不同句子中语义是不一样的,所以我们在输入当前单词的时候,也需要把前面一些单词记录下来,也作为输入给到模型。
所以,我们能否设计一个 1)动态感知输入token;2)不仅能够感知当前token,还可以感知到以前的token。这个就是 RNN (Recurrent Neural Network)。
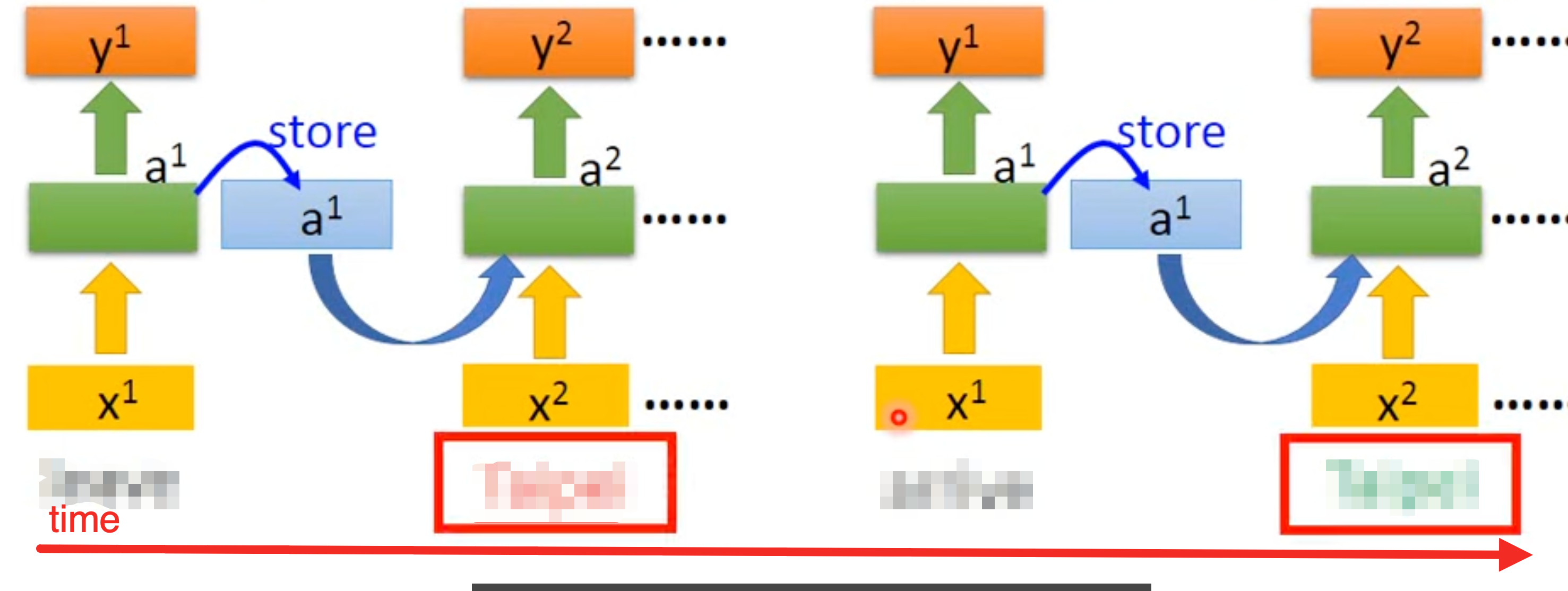
所谓的RNN,核心就是在原来FCN的基础上,增加了循环的机制,可以感知上一次的输出。它的数学表达如下:
$ h_{t-1} = \sigma(W_{xh} \cdot x_{t-1} + b )\
h_t = \sigma(\underbrace{W_{xh} \cdot x_t}{\text{处理当前输入}} + \underbrace{W{hh} \cdot h_{t-1}}_{\text{处理过去记忆}} + b)
$
通过数学公式可以看出来,RNN的核心就是将上一次的输入计算的结果作为下一次的输入代入进来。Python代码如下所示:
1 | import torch |
但是有一个细节,假如权重是0.9,那么随着传递层数的增加,$ 0.9^{n} $会趋近于0。说明RNN不能记忆太长的输入,过长的输入会令RNN”遗忘”(这被称为梯度消失问题)。所以又诞生了 LSTM 来通过 Input Gate、Output Gate、Forget Gate 来决策记忆的存储时机,更加精准地控制模型的遗忘频率。
模型的参数究竟是什么?
从上面的FCN、CNN和RNN模型,我们可以知道,模型本质上就是$ y = \sigma(kx+b) $,所以,所谓的参数就是$ k $(权重,即 w)和 b(偏置)。只不过真实的模型有 n 个 x,和 m 个 y。当 n$和 m(以及中间的隐层神经元)越多,权重和偏置就越多,经过训练的模型也就越“聪明”,这就是后来业界”大模型”的通俗理解。
训练模型,也就是通过各种数学方案,计算出最有效的权重和偏置。拿GPT-3举例,它有175B(1750亿)的参数,说明它的各个神经元中的 w 和 b加到一起是1750亿个。
TODO-超参数。
模型是如何理解自然语言的?
到目前为止,我们知道了模型是如何做推理的——即给定一个x的输入(x为张量),通过一系列公式的运算,得到一个输出。那么问题来了,无论是FCN、RNN还是CNN,它们只能做浮点运算,限定的输入都一定是一组数字,这对于普通的数学预测还好说。但是,对于目前如火如荼的自然语言处理来说,我们如何把自然语言转化成数字让模型理解呢?
One-Hot
最简单的理解方式,就是我们可以通过boolean数组的映射解决。给定一个固定长度的boolean数组,通过在不同的index上标识为true来定义不同的token。假设你的词表里只有5个词:["我", "爱", "学习", "AI", "猫"]。 “学习”这个词的表示就是:[0, 0, 1, 0, 0]。
One-hot有两个致命问题,导致它无法用于 LLM:
- 稀疏性与维度灾难: 真实的词表有几万甚至几十万个词。每个词都是一个长度为 50,000 的向量,里面有 49,999 个 0。这极其浪费计算资源。
- 由于没有语义关联(Semantic Meaning): 在 One-Hot 空间里,所有词之间的距离都是一样的。**”猫”和“狗”的距离,与“猫”和“冰箱”**的距离一样远。模型无法知道”猫”和”狗”是相似的。
Embedding
我们可以通过embedding的方式,将one-hot的高维稀疏向量压缩成一个低维稠密向量。 例如,将”猫”映射到一个 512 维的向量中:
$ \text{Embedding(cat)} = [0.21, -0.54, 0.03, …, 0.99] $
在这个新的向量空间中,语义相似的词,在几何空间上的距离会更近。举个例子,我们可以近似的认为
$ “国王” - “男人” + “女人” \approx “女王” $
那么,我们如何得到这样一组能记住词汇关系的稠密向量呢?方法很简单,就是通过FCN进行无监督训练和转换即可。下面举一个例子:
计算”机器 学习 改变 了 世界”的5维one-hot向量,转为3维的稠密向量
- 定义这五个token的one-hot向量,如_学习_的one-hot向量是$ x = [0, 1, 0, 0, 0] $
- 定义一个线性回归网络,W为5x3结构,将”学习”的x代入如下:
$ h = x \cdot W_{in} = [0, 1, 0, 0, 0] \cdot
\begin{bmatrix}
w_{0,0} & w_{0,1} & w_{0,2} \
\mathbf{w_{1,0}} & \mathbf{w_{1,1}} & \mathbf{w_{1,2}} \
w_{2,0} & w_{2,1} & w_{2,2} \
\vdots & \vdots & \vdots \
w_{4,0} & w_{4,1} & w_{4,2}
\end{bmatrix}_{w初始为随机浮点数} $
- 接着,通过$ h $与另外一个转置矩阵$ W_{out} $计算点积:
$ z = \sigma(h \cdot W_{out} = h \cdot [u_0, u_1, u_2, u_3, u_4]) $
- 此时能够得到”学习”与原句子每个token之间关联的概率。假如说算出来的点积结果如下:
$ \hat{z} = [0.05, \quad 0.02, \quad \mathbf{0.80}, \quad 0.01, \quad 0.12] $
则表明”学习”后面接”改变”的概率是80%,但是我们希望是100%,此时就需要通过反向传播更新W的数值。最后,经过多轮训练后,$ W_{input} $即是我们最终的embedding向量。
机器是如何学习的?
在前面,我们已经多次强调过,我们需要训练模型让模型自主学习。那么模型是如何学习的呢?
在深入了解模型的学习逻辑之前,我们要先理解两个术语。分别是前向传播(Forward Propagation)和反向传播(Backpropagation)。
前向传播
前向传播的解释其实很简单,我们在上文中进行FCN、CNN、RNN的过程,就叫前向传播,用公式表示如下:
$ y_{pred} = \text{Model}(x) $
在前向传播的计算过程中,参数(Weight 和 bias)都是已知和给定的。事实上,当我们在使用GPT或者Gemini的时候,模型在输出答案的过程,就叫前向传播。
反向传播
反向传播与前向传播相反,指的是再已知$ y_{pred},y_{true},LearningRate $的情况下,计算出参数$ Weight, Bais $的过程。
为了定义$ y_{pred} $和$ y_{true} $之间究竟相差多少,我们一般通过损失函数(Loss Function)来衡量,也就是我们训练模型常说的Loss,Loss越大,说明模型的结果越差。常见的损失函数就是均方误差(Meaning Squre Error):
$ Loss = (y_{pred} - y_{true})^2 $
为了让Loss变小,我们就需要反向传播,利用梯度下降(Gradient Descent)算法,通过微分计算出新的权重,公式如下:
$ W_{new} = W_{old} - \text{learning_rate} \times \text{Gradient} $
Learning_rate就是变化的步长,决定了每次训练权重的变化幅度。关于Gradient如何计算,大家可以自行搜索,此处不详细描述,一个反向传播的例子如下:
1 | import torch |
为什么得显卡者得天下?
在探究这个问题之前,我们先分清楚CPU和GPU的区别:
- CPU:CPU的核心少而强大(如我们平常的服务器核心是8核),负责复杂的计算和逻辑分支处理(在计算单元的基础上增加cache和控制单元等)。
- GPU:GPU的核心多而简单(随便一个就是4096核),每个核心能力有限,只能负责简单的加减乘除,无法处理复杂逻辑。
从模型推理和模型训练可以得知,无论是前向传播还是反向传播,都会涉及到大量的向量乘积运算、以及微分(求导)—— 它们本质上都是简单的浮点运算。这些简单的浮点运算基本不会互相干扰,所以它们天生就是可以被”并行”计算的,所以它极适合GPU架构。
举个例子,如果我们要计算两个 1000x1000 的矩阵,这意味着我们要进行 10亿次级别 的乘加运算。对于一个8线程的CPU来讲,即使8个并行处理,它也还要处理非常久。而GPU拥有更多的核心,所以处理显然也就更快。
参考资料
- 李宏毅资料:油管,、B站
- Gemini
- datawhale:https://github.com/datawhalechina